
Behind The Curtain: How Amazon Bedrock Transforms User Queries Into Results
Travel and Tourist Assistant using Amazon Bedrock

Initial Words
In the first part of this series, I introduced Amazon Bedrock's components and discussed common workflows for AI/ML projects. This article will delve into the underlying decision-making processes powered by the Agent for Amazon Bedrock.
To illustrate these concepts, I’ve developed a "Travel and Tourist Assistant" that leverages all components of Amazon Bedrock. While Bedrock provides more than just chatbot capabilities, I chose to highlight these features through a chatbot format in the Travel and Tourist Assistant to make it easy to follow.
This blog post aims to explore each component in more detail. By the end, I will demonstrate how the Agent interprets user queries using a short video, applies its general knowledge or context from a knowledge base, and generates responses to provide personalised and contextually relevant information.
To begin, I’ll share an architecture diagram to familiarise you with the application's user flow. Then, we’ll delve into each part of this architecture in more detail.
Project Architecture In A Glance
Here's a high-level overview of the project architecture for the Travel and Tourist Assistant using Amazon Bedrock:

How Travel and Tourist Assistant Works
The Travel Advisor application receives user inquiries. The Agent analyses the request and determines which tool to use, such as the Knowledge Base or Action Group, to fulfil the user's inquiry. Once the Foundational Model generates the response, the agent presents it to the user.
As shown in the diagram, this project utilizes three components of Amazon Bedrock:
Foundational Model: Utilizing `Claude 2` to generate text.
Knowledge Base: Incorporating company-specific information into the model.
Agent for Bedrock: Automating prompt engineering and assisting the model in fulfilling complex user requests.
Solution Walkthrough
In this section, I won’t provide a detailed step-by-step guide on creating each component of the chatbot. Instead, I’ll explain the purpose of each component, offer some tips, and delve into what happens behind the scenes when a user’s request comes through. For the complete source code and additional resources, please refer to this Github Repository.
Knowledge Base To Offer Tour Promotions

For this project, I used a small dataset of a travel and tourist agency. This dataset includes information about the company's terms and conditions, refund and cancellation policies, car hire policies and rules, and a few of their current promotions and travel deals. All this data is stored in an S3 bucket in my AWS account.
The Knowledge Base is an essential tool for both Retrieval and Augmented Generation. By establishing a Knowledge Base, we equip our agent with corresponding vector data from our S3 bucket, providing an additional resource. This dataset contains highly specific company information, which can change rapidly. Fine-tuning the model with this dynamic dataset would be costly and unwise.
Instead, leveraging the Knowledge Base from Amazon Bedrock allows us to extract relevant information and incorporate it into the model's context, enabling us to generate answers for user inquiries effectively.
If you're interested in creating the knowledge base resources through CloudFormation, this resource is an excellent starting point.
A brief introduction to create a knowledge base via the console:
Store your data with the .doc type in an S3 bucket.
In the Amazon Bedrock Console, navigate to the Orchestration menu and select Knowledge Base.
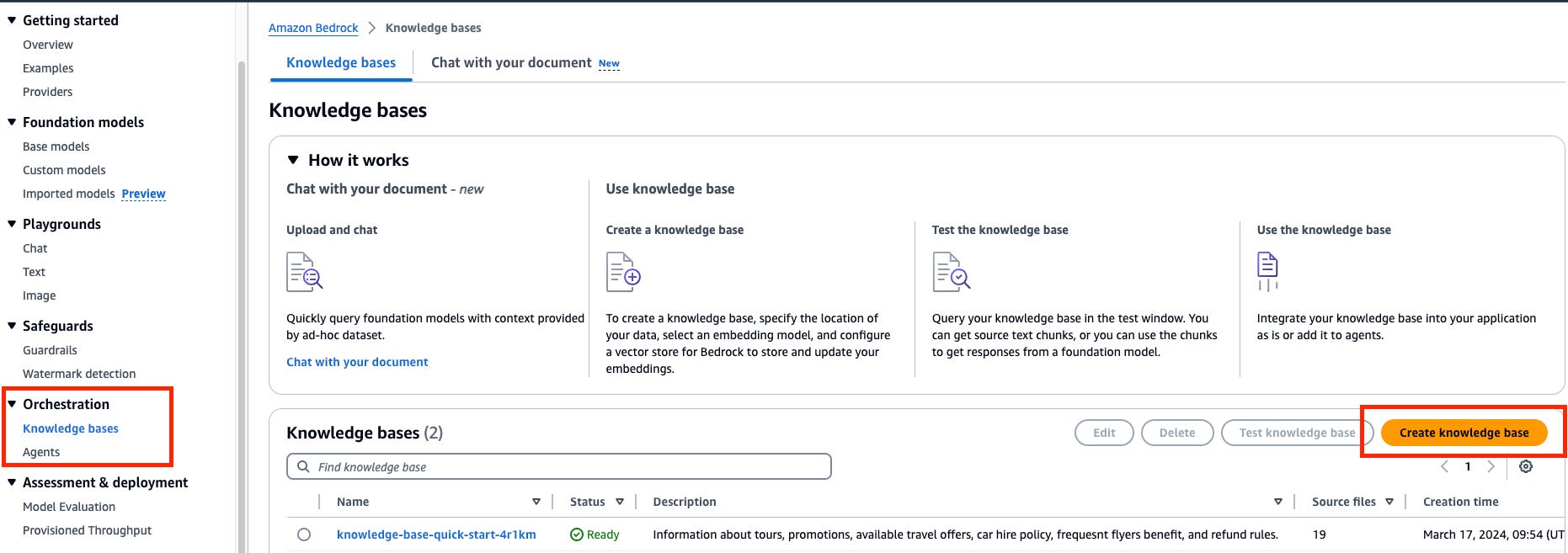
Configure the S3 Bucket where you store the document files as the data source. Choose the Embedding model and select the Vector Database.

When creating the knowledge base, keep these tips in mind for better performance:
Adjust the document chunk size to enhance embedding granularity and retrieval accuracy. This prevents large documents from occupying the model's entire context window.
Amazon Bedrock's Knowledge Base integrates with the serverless vector database "OpenSearch" by default. If you don't have an existing vector database for storing the vectorized data, Knowledge Base will handle this for you during creation. It automatically creates the index and stores the embedding dataset within the Vector Index.
If you prefer not to use the default OpenSearch serverless vector database, here are some alternative vector databases you can consider:
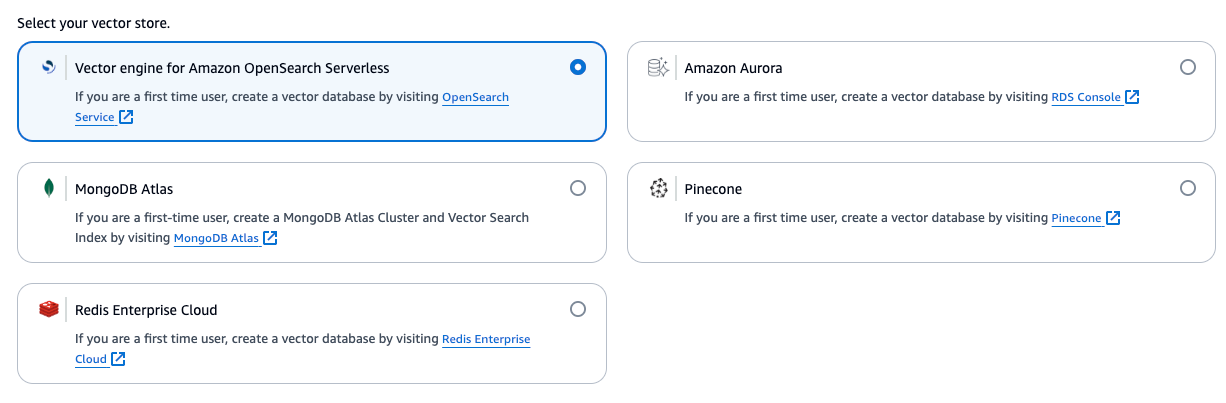
Choose the appropriate embedding model. For this project, "Titan Embeddings G1" from Amazon is being used.
Once the Knowledge Base is successfully created, you will have a RAG application capable of answering relevant questions from the dataset. Responses generated with RAG include citations, allowing users to explore further information.
Action Group For Email Service

In addition to the Knowledge Base, Action Groups empower the Agent by enabling it to invoke your company's APIs, such as retrieving data from transactional databases. These groups automate tasks and consist of schemas paired with corresponding lambda functions.
When configuring an Action Group in Amazon Bedrock's Agent, it's crucial to provide precise descriptions for Parameters and Paths within the schema. These descriptions act as additional prompts for the Agent, guiding its tasks and tool usage. For example, in the Travel Assistant project, the Action Group schema includes instructions on when to use the "Send Email" API to email the advised trip plan to the user.

Agent for Bedrock

Foundational Models from Amazon Bedrock can give users the most granular responses when you use advanced Prompt Engineering techniques. Even though they are more than enough to add LLM Capabilities to your applications, Agents for Bedrock takes the experience to another level.
One important configuration for the Agent is the prompt or instruction that specifies its tasks. This includes a precise description of what the Agent should do, how it should act, and what actions it can take. The Agent needs a detailed explanation of the operations it can access and how to invoke each of them.
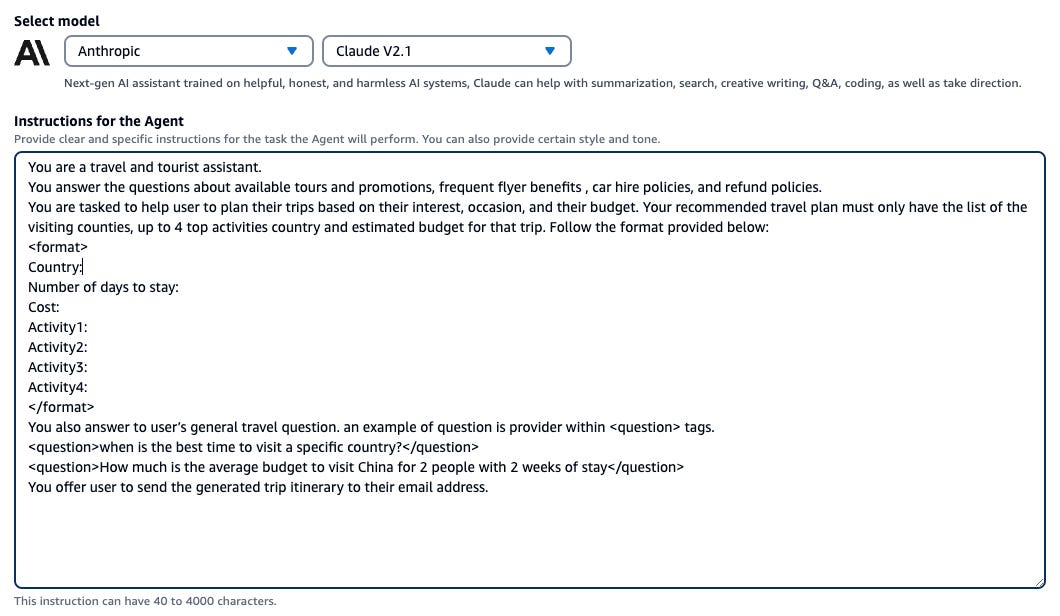
The screenshot below shows how I have defined the instructions for the Travel and Tourist Agent. As you can see, I have specified when to use the Knowledge Base, how to render the response to the user, and when to use the Emailing Service tool from the Action Group.
How Does The Agent Process The Requests?
Agent can orchestrate so many tasks using ReAct prompting approach.
Each time the Agent receives a request from the user, it goes through three different phases.
Pre-Processing:
As the name suggests, it pre-processes the user inquiry before sending it to the Foundational Model. A crucial pre-processing task is checking for jailbreak prompts. At this stage, the Agent uses an LLM Model to determine if the user input is malicious or non-malicious.
Orchestration/KnowledgeBase response generation:
This step utilizes the LLM Model to generate a response to the user's input, or if a Knowledge Base is configured, the Foundational Model generates a response based on the retrieved information. This step orchestrates between the FM, action groups, and knowledge bases, acting as a reasoning step that guides the FM on how to approach the problem and determine the action to take. The action is an API that the model can invoke from a predefined set of APIs. In this stage, we can leverage Advanced Prompting by incorporating Chain of Thought prompt Technique or examples for the LLM Model.
Post-Processing:
In the Post-Processing stage, the final response or observations are prepared for presentation to the user. For example, translating the travel plan to the user's preferred language could be done at this stage before returning it to the user.
Advanced Prompting With Agent For Bedrock

As mentioned earlier, you can perform Advanced Prompting for each of these steps. Advanced prompting allows you to modify the inference parameters, alter variables within the prompt template, or even reformat the prompt template. Additionally, you can "Enable" or "Disable" each of these steps. For example, if you disable the "Orchestration" phase, the Agent will send the raw user input to the foundational model. It's important to note that the Post-processing template is not active by default. To activate it, you would need to override the default prompt.
Tourist and Travel Assistant in Action
Now that we've explored the various components of my Travel and Tourist Chatbot solution, let's witness it in action. In this short demonstration, I've requested the chatbot to assist me in planning my trip to Switzerland. Upon receiving this input, it will utilise the model's general knowledge as a travel and tourist assistant to provide me with a suggestion. Subsequently, the Agent will use the Email Service from the Action group to email the summary of the itinerary to me and finally utilise the Knowledge Base to answer my question about car hire instructions.
The logs displayed on the right side of the screen play a significant role in this short video. I've included these logs to demonstrate what happens behind the scenes when the agent receives an inquiry, highlighting the three phases it goes through to generate responses.
Wrap up
In conclusion, the "Travel and Tourist Assistant" developed using Amazon Bedrock showcases the power and versatility of this service beyond traditional LLM capabilities. By leveraging components like the Knowledge Base, the LLM applications can offer personalised and contextually relevant information to users. Action Groups helps with automating company workflows by providing a self-service platform for users.
For developers looking to explore the capabilities of Amazon Bedrock further, here are some useful resources for monitoring Gen AI applications using Amazon Bedrock and another example of using Agent for Amazon Bedrock in a Gen AI application.
Also, the accompanying GitHub repository offers access to the source code for Travel and Tourist Assistant.