
Scale your applications on GKE with pubsub queue depth metrics
Scale up when there's work to do, scale down when there isn't.


In many distributed systems, Cloud Pub/Sub is the glue that connects them together. According to the product page:
Pub/Sub is an asynchronous and scalable messaging service that decouples services producing messages from services processing those messages.
In this post we’re going to discuss how we can scale our microservices running on GKE by configuring the horizontal pod autoscaler (HPA).
But first: if you haven’t already, consider subscribing to the cloud engineering blog. We’re new but we’re publishing all the time and we’ve got a few writers adding content regularly, and would to know our writing is useful! It’s completely free.
Now, onto the tech.
Background
For those unfamiliar, the HPA is a service which can be used to monitor certain metrics and dynamically update a kubernetes deployment to increase or decrease the number of replicas. From the kubernetes docs:
In Kubernetes, a HorizontalPodAutoscaler automatically updates a workload resource (such as a Deployment or StatefulSet), with the aim of automatically scaling the workload to match demand.
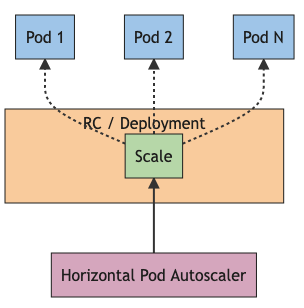
How to?
On Google Cloud’s hosted version of kubernetes, GKE, the HPA can be configured to read GCP specific resources, such as (in this case) Cloud Pub/Sub. Let’s take a look at the YAML.
kind: HorizontalPodAutoscaler
metadata:
name: my-service-service-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-service-service-deployment
minReplicas: 3
maxReplicas: 300
metrics:
- external:
metric:
name: pubsub.googleapis.com|subscription|num_undelivered_messages
selector:
matchLabels:
resource.labels.subscription_id: my_pubsub_subscription
target:
type: AverageValue
averageValue: 100
type: ExternalDiscussion
From the YAML config file above, we can see a few things going on in our autoscaler. The first is that we define a min and max of the number of pods we want to scale to/from. Next we have a metrics block defined, with a metric name that reads from:
pubsub.googleapis.com|subscription|num_undelivered_messagesThis is the number of currently undelivered messages in the Cloud Pub/Sub subscription that haven’t been completed by the service yet. With that metric, we can then define which subscription we want to look at which in this case is my_pubsub_subcription. With the metric set against the queue we have, we can now consider what values we want to use against that target, which in this case is a type of “AverageValue”. Then we specify that value to be 100.
So if the queue depth gets to about 100 message as a moving average, the HPA will bring up another pod in order to start processing more messages since there is a bottleneck of messages beginning to occur. Additional pods will be able to process the backlog of messages and then as the average drops down, then we’ll start removing pods.
The HPA will scale the pods accordingly to maintain that average value as much as possible noting that it won’t go further down than the minimum or above the max. Hypothetically if the queue has an average of 430 messages, then the scaler will add as many additional pods as it needs to until that average comes back down to 100 or less.
If you’d like to read more about the algorithm used for the HPA and how it works, the Kubernetes docs have an excellent explanation.
All done! Now your workloads processing messages in your application will automatically scale based on how many are in the backlog waiting for processing!